Managing data for reproducible research and reuse in knowledge production is a trans-disciplinary priority in the research community. In light of movements like "open science" and federal data sharing requirements there is an increasing need for resources to aid researchers in effectively and efficiently managing their research data throughout the research lifecycle. It is with the current research landscape that this Research Data Management (RDM) Hub was created.
The RDM hub shares the services that the University of Miami Libraries provides for research data management, as well as educational resources to assist you in managing your research data.
This checklist takes you through the basics in managing your data throughout research lifecycle.
☐ Capture Key Project Information - Record key project information at the beginning of your research for use throughout the project.
☐ Review Relevant Policies - Review University of Miami policies and guidelines at the bottom of Storage & Backup. Review Data Management & Sharing policies from funding institutions by seeing Funder Data Policies.
☐ Write or Review a Data Management & Sharing Plan (DMSP) - A DMSP is a document that helps you think through and outline what will happen to your data during the project. DMSPs are often required by funding institutions.
☐ Budget for Data Management and Sharing - Be aware of associated costs for data management resources and data storage. These costs may be allowable costs for grant funding.
☐ Define Roles & Responsibilities - The roles and responsibilities of team members should be clearly outlined in shared team documentation. Regularly review roles.
☐ Establish Data Organization - Decide on file naming conventions and file structure. Each member of your team should use the agreed upon organization structure. For more on organizing your data, see File Mangement.
☐ List Data Types, Formats, & Size Understand and record the data that you are working with and the implications for security, storage, and sharing. Record in the DMSP and/or README. For more on data types and formats, see File Mangement.
☐ Outline Data Collection Methods - Explain how new data will be collected. Describe any existing data that is being used. Record in the DMSP.
☐ Utilize Metadata Standards - Consult community standards when creating metadata: metadata schemes, controlled vocabularies, ontologies, and technical standards. For more on metadata, see Documentation
☐ Create Data & Code Documentation - Document data and code information (such as variable definitions, units, functions) in a README text file, data dictionary, or codebook. Good documentation allows for effective reuse. For more on creating documentation, see Documentation.
☐ Document Data Analysis Actions - Document data analysis protocols, data cleaning actions, tools used, and potential limitations.
☐ Document Image Management & Processing - If data includes images, document manipulations and analysis of images. Share in non-proprietary formats when possible.
☐ Secure Active Data - Ensure confidential and sensitive data is stored properly and has appropriate access restrictions and security controls. For more on securing your active data, see Storage & Backup.
☐ Determine Appropriate Data Storage Locations - Review institutional storage options to decide where your data should be stored. Data types and security level will inform the decision. For more on determining the appropriate data storage location, see Storage & Backup.
☐ Create a Data Backup Plan - Review institutional backup services to help prevent data loss. Consider implementing the 3-2-1 Rule.
☐ Resolve Data Access Problems - Grant data access to authorized team members. Plan for granting appropriate access to new hires and removing access for team members who have left the project.
☐ Appraise Data for Archiving - Determine what data should be retained as part of the historical record and qualifies for permanent storage.
☐ Appropriately Dispose of Data - At the project's conclusion, identify which data and records are safe to dispose of and not needed for data retention purposes. For more on data retention and destruction, see Storage & Backup.
☐ Determine Data Ownership - Resolve any data ownership issues to confirm approval to share the data. Questions should be directed to PIs and the university's Office of Technology Transfer (OTT) via techtransfer@med.miami.edu. For more on data ownership, see Data Licensing & Copyright.
☐ Review or Create Data Use Agreements - A Data Use Agreement (DUA) is a contract between a data producer and data reuser. A DUA can impose rules for data reuse and handling. A DUA is useful for sharing sensitive data. For more on DUAs, see Data Licensing & Copyright.
☐ Fulfill Data Sharing Requirements - Consult your funding agency's data sharing policies for specific requirements. Additionally, check if your publisher has a data availability policy.
☐ Check Against FAIR and CARE Principles Publish your data with a clear license, documentation, and metadata to ensure that your data is Findable, Accessible, Interoperable, and Reusable. Consider the Collective Benefit of sharing; confirm that you have the appropriate Authority to Control the data; that you are sharing Responsibily; and that Ethics are considered when deciding to share.
FUNDAMENTAL BEGINNINGS OF RESEARCH DATA MANAGEMENT
Best practices suggest that you will want to record important information at the beginning of your research so that you can easily access it as the project continues and evolves. Record information such as:
The project name
The associated grant number, if you have one
The Principal Investigator's name, contact information, ORCiD
A brief description of the project
You may record this key information in a notebook (physical or electronic) or a Data Management & Sharing Plan. Wherever you decide to record this information, make sure you can easily locate the notebook or document.
Record Roles & Responsibilities
If you are working in a team environment, it is useful to record and define the roles and responsibilities of your team members. This will help in limiting miscommunication and duplicative work. PIs are recommended to specifically assign someone the role of overseeing the data management for the project. Additionally, each defined role could have additional responsibilities that directly relate to the creation of good data.
Regular Team Check-Ins
Make sure your team members have access to these documents and understand their roles. Consider setting up regular check-ins with your team to allow for any questions, provide updates, and double check that everyone is on the same page. Regular meetings can help to create an inviting work environment and help your team do better research.
FAIR DATA PRINCIPLES
"One of the grand challenges of data-intensive science is to facilitate knowledge discovery by assisting humans and machines in their discovery of, access to, integration and analysis of, task-appropriate scientific data and their associated algorithms and workflows." - Force 11 FAIR Data Principles
In 2014 the Future of Research Communications and e-Scholarship (FORCE) working group began developing a set of principles for the dissemination of scientific data and other digital products that come from research. This effort produced a set of best practices for data publishing, known as the FAIR principles. The acronym gives us an outline of this set of best practices, but please see their full set of guidelines. In 2016 the ‘FAIR Guiding Principles for scientific data management and stewardship’ were published in Scientific Data. In this article, the authors intended to provide guidelines to improve the Findability, Accessibility, Interoperability, and Reuse of digital assets.
FFindableRich metadata with assigned DOI AAccessibleMetadata and data available across open protocols IInteroperableData and metadata use standard or easily understood data structures RReusableMetadata includes provenance and uses community accepted descriptions
In response to the FAIR Principles, the Global Indigenous Data Alliance (GIDA), created the CARE Principles for Indigenous Data Governance. While the FAIR Principles focus on human and machine readability to increase overall data sharing, the CARE Principles are people and purpose-oriented. These principles attempt to fully engage with Indigenous Peoples' rights and interests, and to provide agency to Indigenous Peoples in the application and use of their data and knowledge.
CCollective BenefitData ecosystems shall function in ways that enable Indigenous Peoples to derive benefit from the data AAuthority to ControlIndigenous Peoples' authority to control their data must be empowered RResponsibilityShare how those data are used to support Indigenous Peoples’ self-determination and collective benefit EEthicsIndigenous Peoples’ rights and wellbeing should be the primary concern
While designed to protect Indigenous Data Sovereignty and self-determiniation, the CARE Principles can be widely applied to all forms of research data publication. Indeed, these principles have inspired larger conversations around the ethics of data sharing and the idea of patient-owned data, where a patient may have control over who can access and use their data. Whenever sharing data, researchers must think critically and consider the ethical implications of making the data publicly available. Just because a dataset can be shared, does not mean that it should be shared. Even when data sharing is required, researchers should consider the most responsible and ethical way to share the data, such as using a Data Use Agreement. For more on ethical sharing, please email the Research Data team at researchdata@miami.edu.
Data Management & Sharing Plan Services
The University of Miami Libraries can assist researchers in creating and reviewing a Data Management & Sharing Plan (DMP or DMSP).
If a researcher is using the DMP Tool to draft their plan, they can utilize the "Request Feedback" feature when logged into the DMP Tool website with their miami.edu email. This will share a draft of their DMSP to one of our data librarians for feedback.
Researchers who would like training on writing a DMSP can email researchdata@miami.edu to set up a training session.
What is a Data Management & Sharing Plan, and Why is it Important?
The Data Management & Sharing Plan (DMSP), also sometimes known as a Data Management Plan (DMP), is a written statement that describes the data you expect to acquire or collect throughout your research, how you will collect, organize, document, and analyze the data, and finally how you will share, publish and preserve the data.
The DMSP will share information about:
Data and data formats
Descriptive documentation
Policies for access, sharing, and reuse
Long-term storage and preservation
Budget
The process to create a DMSP is an opportunity for you to think through different stages of your research from grant writing to post-publication. It is likely that during the research your plan will change, but by writing out a plan and formalizing the management process you will be better prepared for the changes that come, your research workflow will be more efficient, and your research will have more impact. In addition to the organizational benefits to writing a DMSP, many federal and private funding agencies require a DMSP.
DMSP RESOURCES
Assistance While Writing a Data Management Plan
Have a plan? Contact us for a Data Management Plan Review.
There are online tools that help researchers write their plans. These tools provide guidelines for creating a DMSP and offer DMSP organization based on different granting agencies and funding source requirements. These tools will save researchers time and effort as they seek to understand specific requirements from the funding source for which they are writing a grant.
The University of California's California Digital Library (CDL) maintains the DMP Tool as a collection of resources and step by step guides to help researchers create a data management plans specific to particular agency requirements. The DMP Tool maintains templates for data management plans that are based on the specific requirements listed in funder policy documents. A little time with this tool before creating a data management plan will streamline your writing process. The University of Miami maintains an institutional affiliation with the CDL and the DMP Tool. Faculty, students and staff can login with their University of Miami email (@maimi.edu) and have full access to the collection.
The United Kingdom Digital Curation Center in conjunction with the Joint Information Systems Committee maintain an online DMP Tool with resources collected from European funding agencies and organizations. This is a useful resource for those with research connections in Europe. Like DMP Tool, DMPOnline maintains templates for data management plans that are based on specific requirements listed in European funder policy documents. For institutional access, sign up for a DMPOnline account with your University of Miami email (@maimi.edu).
The DMP Assistant is a national, online, bilingual data management planning tool developed by the Digital Research Alliance of Canada (the Alliance) in collaboration with host institution University of Alberta to assist researchers in preparing data management plans (DMPs). The DMP Assistant maintains templates for data management plans that are based on specific requirements listed in Canadian funder policy documents. For institutional access, sign up for a DMPOnline account with your University of Miami email (@maimi.edu).
Data Publishing Services
The University of Miami Libraries can assist researchers publish their data in a discipline specific repository or in the University of Miami scholarly repository, Scholarship@Miami.
Data Publishing Services include:
Researchers can book a consultation to learn more about the options for publishing data outside of the University of Miami. Our data librarians will be able to provide feedback on the data deposit and assist the researchers in locating an appropriate data repository. To book a consultation please email researchdata@miami.edu.
The University of Miami libraries provide data curation and publication services which places the data in the institutional repository and assigns a DOI that will always resolve to the published data. Researchers can contact a data librarian to begin this process. Our data librarians will review the researcher's data and documentation following the FAIR and CARE principles to ensure the data are as complete, understandable, and accessible as possible. The data librarians will then publish the researcher's data into Scholarship@Miami and assign a DOI to the publication. Please email researchdata@miami.edu to contact data librarians for data curation and publishing.
Please view the Data Publishing Checklist below for a guide to begin publishing your data in Scholarship@Miami.
The ORCiD is like a driver's license for academic researchers. It is a way to make sure that you are identified as you, and not another author/researcher with your same name or initials.
Most journal publishers now require authors to have an ORCiD to submit a manuscript. For publishing data, it is also considered a best practice to identify yourself with an ORCiD. It takes a few minutes to register for an ORCiD and connect it to the University of Miami at https://orcid.scholarship.miami.edu/. Make sure to use your UM email address to create the account.
If you already have an ORCiD, please also take a moment to connect it to the University of Miami. It is a simple process that starts here. If you want more information please see the ORCiD@UM FAQ.
☐ Write abstract for data publication (including several keywords).
☐ Identify all data creators, institutional affiliations, and contact information.
☐ Decide on the appropriate license for the data publication.
☐ Create metadata for the whole dataset as a README.txt file (authors, title, abstract, notes). See the University of Miami Libraries TemplateREADME.txt.
☐ Create metadata for any tabular data included (column headers, units, abbreviations)
☐ Confirm that a colleague in your discipline could reuse your data and descriptive metadata without your help.
☐ Confirm that you have all the correct permissions to distribute any data and/or code in the package.
☐ Transform all data files to formats identified as best practices within your discipline.
☐ Create data package as a single archive file (zip file, for example).
Once you have all of this material gathered together, please contact us and we can provide a review of the material if it is going into an already identified disciplinary or third party repository (see Data Repositories in the table of contents on the left), or we can facilitate the deposit and publication of your data in the UM Scholarly Repository, Scholarship@Miami.
DATA SHARING & DATA PUBLICATION
Why publish or share data?
Publication of data as a supplement to journal article publications or as a stand alone data publications is increasingly recognized as good scholarship within many disciplines. Your work becomes more visible, has more impact, is easier to reuse, and is more likely to be preserved for the future. Additionally many funding agencies and journal publishers now have data sharing requirements.
What are the options to share or publish data?
There are many forms of publishing or sharing data, but most require the deposit of the data into an online data repository. First you must identify an appropriate repository for your data (see Data Reuse for more on data repositories). Then you must prepare your data, including creating and assigning appropriate metadata and formatting your data, both according to best practices for your discipline and the particular repository.
Finding the right place – identifying a repository
There are literally hundreds of data repositories. It is a good idea to identify a repository for your data before you begin your research. The University of Miami maintains the scholarly repository, Scholarship@Miami in which your data can be published and shared. Many other data repositories exist that may be appropriate as well (see Data Reuse for more on data repositories).
Preparing your data
With a good Data Management Plan you will prepare your data for deposit as part of your research workflow. This includes creating and assigning appropriate metadata and formatting your data, both according to best practices for your discipline and the particular repository.
Navigating access options
When data is published or shared access rights range from open data that is freely available in the public domain to licensed data that has limited access rights and is served from proprietary publication platforms. For more information, see Data Licensing & Copyright.
DATA CURATION
Data curation that follows the FAIR Principles ensures that datasets are complete, well-described, and in a format and structure that best facilitates long-term access, discovery, and reuse.
The University of Miami's institutional repository, Scholarship@Miami, is a place for dissertations, theses, faculty scholarly output, and research data produced by the research community at the University of Miami.
Our data curators collaborate with researchers to make data published in Scholarship@Miami more Findable, Accessible, Interoperable and Reusable by aligning with the FAIR Principles.
ARCHIVING vs LONG-TERM STORAGE
There is a difference between permanent retention, or archiving data, and long-term storage of data. Archiving means that your data is actively cared for, to ensure it is maintained and usable into the future. Long-term storage of data works to make research data available in an accessible and persistent format for a specific period of time. This time period may be decided by the funder, your institution, or the data repository that stores your data. Some data repositories work as long-term storage, while some act as archives, so make sure you learn about the services that your repository of choice offers. To learn more about data repositories, visit Data Reuse.
Appropriately back up your files, to ensure your data does not degrade or become corrupted over time.
Perform ongoing migration on your data to the most current technology formats.
Collect and preserve your documentation.
A small percentage of data and related records may be identified for permanent storage as a part of the historical record of a discipline, institution, or as intellectual property. Records eligible for permanent retention may be those that:
document a breakthrough
are generated by a lab or individual who had great impact on the field
are highly reusable in a particular area of research
Make sure the data collection, analysis, and variables are well-documented.
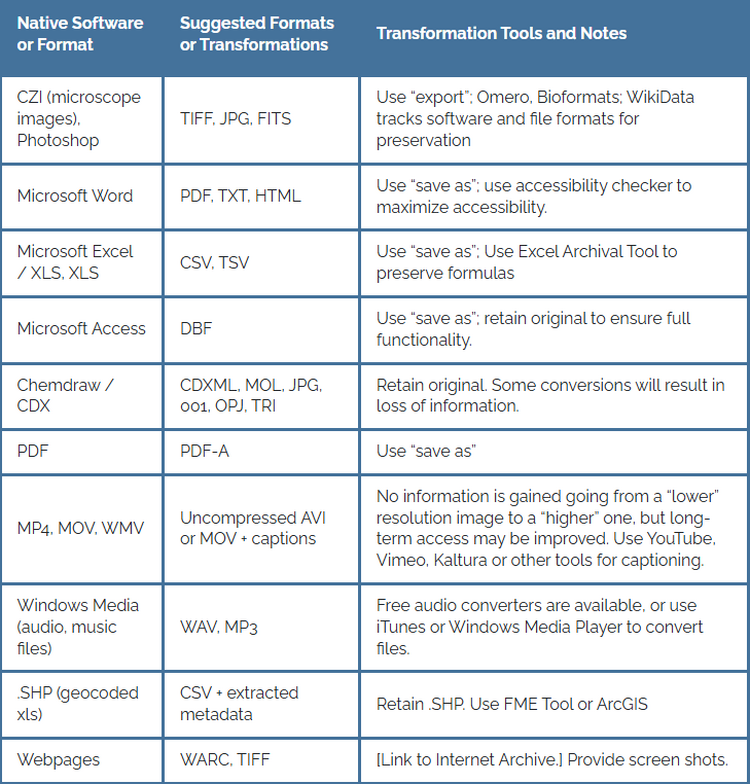
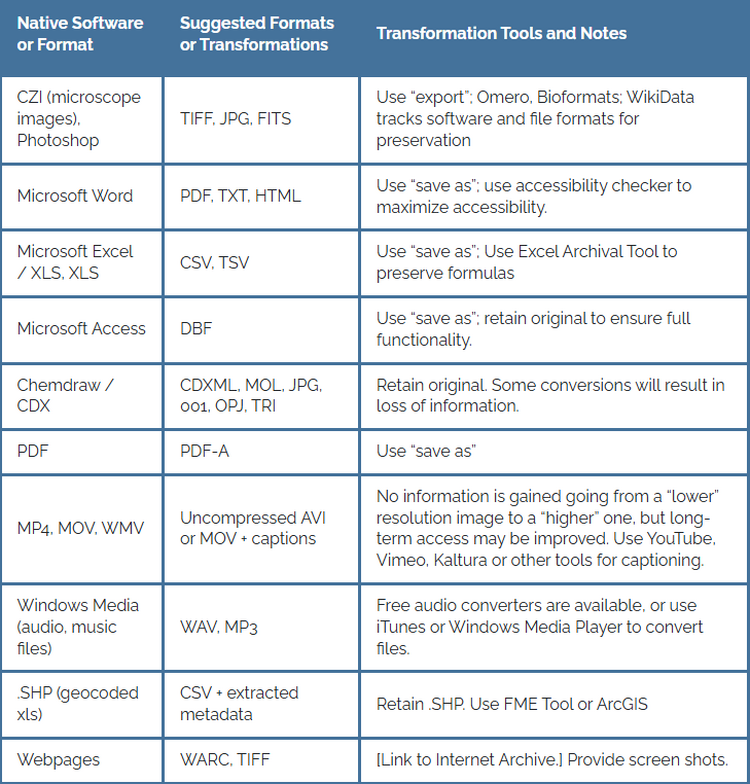
Use a file format that is unencrypted, uncompressed, open/non-proprietary, and widely used by your discipline's community as this will help to sustain access for the long term. Please see the Common Transformations table on File Management.
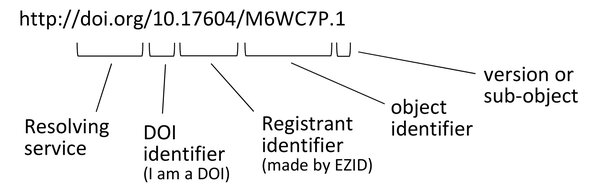
A Digital Object Identifier (DOI) is a permanent online identifier for a digital asset; perhaps a journal article or a supplementary data set for a publication.
What is special about the DOI, is that while the digital object may physically move from one server to another, the link will never break. This is guaranteed by the maintenance of database that links known assets to their physical locations. This service is provided as a partnership between the publisher of the digital asset and the DOI resolving service (e.g. https://doi.org/).
Object: a digital resource (can also be a collection of digital resources)
* Note that both the ARK and the DOI serve the same purpose.
DOI MINTING GUIDELINES
These guidelines will help you determine if minting DOIs for your digital assets is appropriate. Please email researchdata@miami.edu if you meet these guidelines and need a DOI.
When you create the persistent identifier (DOI or ARK) three general requirements must be met:
Data must be open –OR– licensed somehow. This means you want, and have the authority, to make the data available to the general public and the data will be considered a part of the public domain.
The data is considered to be a part of the scholarly record (analogous to a journal article).
You have the intention and ability to store and manage the object such that online access is maintained in perpetuity. This is your responsibility entirely.
You are responsible to provide the minimum required metadata (description) for each object that you assign a DOI or ARK according to the DataCite Metadata Schema (see their latest release example for a simple dataset). You cannot mint a DOI without this minimum requirement.
The metadata shall be in the public domain (can be used freely for discovery).
[ best practice ] The data shall be presented on a landing page with links to the data, the metadata shown, links to any software needed for access, a suggested citation shown, and information on any access restrictions shown (if they exist).
[ best practice ] If you are maintaining a repository, it should strive to be recognized with the Data Seal of Approval set of repository standards and the re3data repository listings.
You cannot share the EZID login with a third party.
You cannot place/store/archive objects on a third party server.
All guidelines/terms here are subordinate to the UM institutional repository guidelines/terms.
These guidelines were adapted from the EZID guidelines/terms for users with minting privilege
It is important for researchers to organize their files so that the research team, as well as researchers using the data in the future, can easily retrieve and understand their files. It is recommended to establish and record file organization conventions before the research begins.
How Can you Organize Your Files?
Directories
Organizing files hierarchically allows the researcher to create relationships within their file structures and categorize their files. Folders and subfolder names should reflect the internal content. Researchers should consider including project name, date, and unique identifiers for the project (such as a grant number). The files within a folder can be maintained chronologically, by classification or code, or alphabetically. No matter how you decide to organize your directory, remember to document the chosen file directory structure and the types of files that belong in each folder.
Example:
Top folder: project_title_grant_number
subfolder: project_title_datasets
2022-2023_project_title_raw_data.csv
2022-2023_project_title_processed_data.csv
subfolder: project_title_semantic_analysis
project_title_semantic_analysis.R
project_title_semantic_analysis_output.csv
readme file: readme_project_title.txt
File Naming Conventions
File names should be unique, short, and informative. A good file name will be machine and human readable. File names may include project information such as: project name, acronym, or research data name; study title; location information; researcher initials; date (consistently formatted, i.e. YYYYMMDD); and version number.
Whatever file naming convention works for you and your team, it is most important to be consistent!
DO
DON'T
UseCamelCasing.docx
use_underscores.txt
2015_put_The_Date_First.csv
20150214_useTwoDidgitDateNumbers.xls
startASeriesWithLeadingZeros_001.doc
20150214_UM_date-place.shp
useFileExtensions.jpg
Leave spaces in the file name.xls
Use the default save name from MS word that is simply the long first sentence in your file.doc
“Working” file formats (i.e, those used when collecting and working with project data) may not be ideal for re-use or long-term preservation.
Principles for selecting file formats
Select open, non-proprietary formats
Open, non-proprietary formats are better for re-use and long-term preservation, as they are independent of costly software for use and may be generated and opened in an open or free software. As a general rule, plain text formats, such as comma- or tab- delimited files, are open formats and are typically better for re-use and long-term preservation.
Example of a proprietary format: Photoshop .psd file
Example of an open format: .tiff image file
Select “lossless” formats
Formats that compress the information in a file are smaller, but the compression may permanently remove data from the file. These formats are “lossy,” while formats that do not result in the loss of information when uncompressed are “lossless.”
Example of lossy formats: .mp3 audio file, .jpeg image file
Example of lossless formats: .wav audio file, .tiff image file
Select unencrypted and uncompiled formats
If the encryption key, passphrase, or password to a file is lost, there may be no way to retrieve the data from the file later, rendering it unusable to others. Uncompiled source code is more readily re-usable by others because recompiling is possible with different architectures and platforms.
"Common Tranformations" - Data Curation Network
Please be aware, that some of the files listed are "lossy" formats.
VERSION CONTROL
It is important to keep track of versions when working with data. Benefits of version control include: the ability to revert data to an earlier version instead of starting from scratch or even regenerating data; the ability to branch out and experiment with new work; and the ability to collaborate and merge changes seamlessly.
Using a file naming scheme such as YourFileName.v1.0.csv.
Using version control software, like Git, GitHub (use with your miami.edu email), or Apache Subversion.
Best Practices for working with Version Control:
Save a copy of the raw, original data that does not get touched. Only work on a copy of the raw data, so that there is always an original version that you can come back to incase of emergencies.
Avoid label such as "revised" and "final". Instead, use a clear and documented file naming scheme (.v1.0 or _v1_0). Look to standards like the Semantic Versioning Specification.
Use tools that automatically assign version numbers or version control software, when appropriate.
Reach out to the Research Data Team at researchdata@miami.edu to learn more about version control and version control software.
STORAGE & BACKUP
Best Practices for Storage and Backups
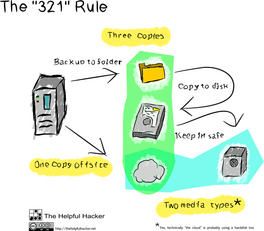
Best practices suggest using the 3-2-1 Rule: retain 3 copies of your files on at least 2 different types of storage media, with 1 copy being held offsite.
Maintain a raw, original copy of your files (that does not get touched) to prevent data loss.
When using a shared storage solution it is important to regularly check access permissions to ensure that each person on the project has the appropriate access to files. It is a good habit to check access permissions when a new person joins the team, or a former member leaves. Doing regular checks on access permissions will help increase data security and efficiency.
Short-Term Options at UM
Short-term storage can be used when regularly accessing and working on files during active research. As its name implies, this type of storage is only intended to be used for a shorter time frame.
Scholarship@Miami - This University of Miami Libraries managed repository preserves and provides access to selected research and scholarly works prepared by faculty, students, and staff of the University of Miami. To add your work, contact repository.library@miami.edu.
Sylvester Data Portal (SDP) - This portal is a novel multi-omics research platform that facilitates the storage, management, analysis, and sharing of biomedical datasets generated at the Sylvester Comprehensive Cancer Center. By leveraging state-of-the-art software and cloud computing technologies, SDP provides Sylvester researchers with well-annotated and FAIR (findable, accessible, interoperable and reusable) datasets, along with well-established bioinformatics tools and automated processing pipelines that enable the intuitive exploration and modeling of their data.
Consider using an automated service to create regular backups. Personal computers often come equipped with backup software, such as Windows Backup and Time Machine for Macs. Do not create your backup right on your local hard drive. Some cloud storage services like Box and OneDrive do provide both storage and backup services. Using cloud services' sync functions is not the same as creating a backup.
Make sure you know how to recover data from your backups before you need to do it in an emergency. Regularly check that your backup system is functioning properly.
If you are working with sensitive data, personally identifiable information (PII), or protected health information (PHI) you should take extra precautions to protect your research subjects and their information. You should consider what type of de-identification work will need to be undertaken. A consent form should inform participants of what will happen with their data after the research is completed. Additionally, reflect on what version of the data, if any, should be shared publicly, or if there should be access restrictions for the safety and privacy of the participants.
The University of Miami’s Faculty Manual states, “In order to respond to allegations regarding the integrity of any published report, adequate records of the original protocols and research records, including all raw data, must be preserved for at least seven years (or longer if required by the funding agency), so they can be made available for inspection.”
DATA DESTRUCTION
The Office of the Vice Provost for Research & Scholoarship's Data Handling Guidelines provides the following guidance on destruction of sensitive data:
Paper/printouts with identifiable or sensitive information that need to be disposed of, should be shredded or placed in the approved University provided Shred-It bins (current vendor) for such information – NOT in the regular trash.
Avoid use of sensitive or identifiable paper documents at home, including printing of such documents.
If you have an unavoidable and approved use case i.e. explicit approval from your business unit leadership, then a plan/practice for proper disposal of such information is critical. Best practice is use of a crosscut shredder which is the preferred solution. At the very minimum, destroy all areas with identifiable information such as name, address, telephone number, email address, MRN, institution/department/business unit or other identifiable information. Again, AVOID use unless absolutely needed. NEVER dispose of University documents with identifiable or confidential/sensitive information in the regular trash.
LICENSING DATA
Creative Commons Licenses
When you publish your data it is considered a best practice to license the data for use within the publication. Currently the most common license used for academic data publications is the creative commons international attribution 4.0 license; commonly known as the CC-BY 4.0 license (creative commons is a non-profit legal entity). Simply put, this means that another person or machine can re-use your data, modify it, and publish it again as long as they give attribution to you as the data creator. Note that the CC-BY license is not a copyright; it is not possible to copyright data in the United States.
The CC-BY license is not appropriate for all data publications. Creative commons includes other restrictions on use such as non-commercial or non-derivative. In the first case, the data cannot be used for commercial purposes and in the second the data cannot be modified and published in derivative works. You can see the full set of creative commons licenses at:
Apart from the creative commons licenses, another organization, the open data commons, publishes another set of licenses that may be more appropriate for highly curated data. You can see the full set of open data commons licenses at:
A DUA is a binding contract between organizations governing the transfer and use of data. DUA terms and conditions vary depending on the laws and regulations governing the particular type of data as well as the policies and/or requirements of the Provider.
Additionally, some data should be protected from open use and sharing without proper conversations around the intended reuse purpose. This is especially important when working with sensitive data that uses human participants, endangered animals, and populations of people who historically have not had autonomy over their data. In this case, you should consider making the data accessible via a DUA.
If you are planning to share data with protected health infromation or your code/sotware, you are required by the UM Inventions, Intellectual Property & Technology Transfer Policy to disclose this data to the Office of Technology Transfer (OTT).
INTELLECTUAL PROPERTY & COPYRIGHT
Intellectual property (IP) refers to different types of intangible expressions (such as artistic and literary work, discoveries and inventions, words, symbols and designs) for which specific monopoly rights are recognized under specific laws.
Intellectual Property and Copyright
In general raw data on their own are considered facts and thus cannot be copyrighted. However, data that are gathered together in a unique and original way, such as databases, can be copyrighted or licensed. It is important to understand data licensing from the perspective of both the data user and data creator.
Sharing data that you have produced or collected yourself
Data is not copyrightable. Particular expressions of data, such as a table in a book, can be copyrightable.
Promote sharing and unlimited use of your data by making it available under an appropriate license to ensure proper re-use and attribution. There are many licenses available that represent the range of rights for the creator and licensee of the data. Two options for providing open licenses for research data are:
Open Data Commons License: set of legal tools and licenses to help you publish, provide and use open data.
Creative Commons License: provides a standardized way to grant the public permission to use their creative work under copyright law.
Sharing data that you have collected from other sources
Licensed data can have restrictions in the way it can be used or shared downstream.
When re-using existing data be sure to clarify ownership, obtain permissions if needed, and understand limits set by licenses.
Be sure to provide appropriate attribution and citation.
If licensing restricts sharing of the data, providing detailed information about where the data were obtained and how the data were analyzed can help with reproducibility.
Additional Resources
This resource from Kristin Briney describing how copyright applies to research data. It is designed to give a clear and brief overview to this sometimes confusing topic: Briney, Kristin (2016). Data and Copyright. figshare. Poster. https://doi.org/10.6084/m9.figshare.3117838.v1
It is important to describe your research and research data sufficiently so that you and data re-users can: understand the data and the context that the data was created in; evaluate if the data can be used for their purposes; and further analyze and reuse the data.
Some types of documentation include:
Descriptive: Information about the data, such as title, author, and related publications.
Project Documentation
Documents project information, such as protocols, equipment, methods, software used for analysis, and any processing or transformations performed.
File Documentation
Often documented in a README file, which documents contents of files and relationships between files.
Variable Documentation
Documents what each variable represents, including units and descriptions of how an absence of data is recorded.
Data Dictionary/Codebook: a Data Dictionary or Codebook is a a way to document the variables used in a a dataset. A Data Dictionary can include information such as variable names, measurement units for the variable, allowed values for the variable, and a definition for the variable.
Metadata Schemas: When appropriate, use an established metadata schema that is used within your discipline. Using a metadata schema helps other members of the disciple to use the same language when looking for data.
Technical: Information that is automatically generated by software and instruments used.
Types of files used (e.g., csv, txt, png, etc.).
README File
Provides a clear and concise description of all relevant details about data collection, processing, and analysis in a README file. This will help others interpret and reanalyze your dataset. This is often the first place that new data users go in order to understand how to approach the data.
README files are created for a variety of reasons:
to document changes to files or file names within a folder
to explain file naming conventions, practices, etc. "in general" for future reference
to specifically accompany files/data being deposited in a repository
Best practices suggest that a README file is saved as a plain text file, for file preservation and greater accessibility.
For assistance with creating a README file, please:
A benefit of sharing your data is that other researchers can expand on your research, or use the data to test a different research question. As discussed in RDM Quick Start, publicly sharing datasets in data repositories helps make the research data more FAIR (Finable, Accessible, Interoperable, and Reusable).
At the University of Miami Libraries, we can assist you with finding data for your research. We can help you:
FigShare started as a way to share data behind published scientific figures and has grown to accept research data from any academic discipline.
Zenodo accepts data from any discipline as well as computer code hosted on GitHub.
There are thousands of domain specific data repositories, some of which existed before the advent of digital data storage. The ones below are very common, but there are many, many more (see the search tool at DataCite Commons).
Dryad is a good repository for data in the life sciences.
ICPSR is a considered the standard for the social sciences.
FAIRsharing.org maintains a registry of knowlegebases and repositories of data and other digital assets.
The OpenDOAR is a quality-assured, global directory of open access repositories.
DataLumos is an ICPSR archive which houses valuable government data. DataLumos accepts deposits of public data resources from the community and recommendations of public data resources that ICPSR itself might add to DataLumos.
Check under which terms and conditions the data is shared. Make sure that there is a licence, and that the licence gives you permission to do what you intend to.
Assess the quality of the data.
Evaluate if the data comes from a trusted source and if it is curated.
Check if the data adheres to a standard.
Verify that the data has been ethically collected and that your reuse of the data conforms with policies and regulations you are expected to follow. For sensitive data, there are usually legal and technical requirements that have to be met before data can be accessed. Getting access to sensitive data will therefore involve additional steps.
If the data you are reusing has been updated, make sure to document which version of the data you are using, and consider what impact the changes may have on your results.
PROPERLY CITE THE DATA
Always remember to cite the data that you use. The data citation should be avaliable on the data repository page. Do not forget to include the DOI in the citation, if one is provided.
There are so many tools for project management and collaboration that exist. Explore a few listed below, but note that there may be a better tool for your needs that is not listed here. The best tool for collaboration is the one that your team will actually use!
The Open Science Framework, or OSF, is a free, open platform to support research and enable connection with research team members internally and externally.
OSF can be used as an collaborative project management tool. With a free account you can make a public or private project to work on with your collaborators. To learn more about managing a project through OSF, schedule a consultation with a librarian or visit the OSF project guidance.
The University of Miami Information Technology provides access to Microsoft Teams, a tool for collaboration within the University of Miami.
Microsoft Teams can be used as a collaborative project management where researchers can communicate, facilitate workflow, share documentation, and record data. Adding the Microsoft Planner app to a Team can help researchers track actions and deadlines. To learn more about managing a project, schedule a consultation with a Data Librarian at researchdata@miami.edu or visit the Microsoft Teams video training.
GitHub is a developer platform that empowers developers to manage version control on their code, collaborate with other developers on projects, and share code with the global community. In addition to these abilities, GitHub can also act as a project management platform for developers.
GitHub Projects allows a development team to connect the planning processes directly to the work that is being done. Within GitHub Projects, development teams can create issues that specifically correspond to projects and repositories within one's GitHub account. GitHub Issues allows for granular project management, progress tracking, and conversations.
SPARC maintains a current list of Federal Agency Requirements for Data Sharing and Article Publication.
GREI at the NIH - The vision of the Generalist Repository Ecosystem Initiative (GREI) is to develop collaborative approaches for data management and sharing through the inclusion of generalist repositories in the NIH data ecosystem. GREI also aims to better enable search and discovery of NIH-funded data in generalist repositories.
FUNDER DATA REQUIREMENTS
Many federal agencies and private foundations who support research require data management plans and mechanisms for data sharing and access as a part of the grant process. These requirements vary between organizations. It is best to identify potential funding agencies and check individual requirements before drafting the Data Management & Sharing Plan.
The term Open data refers to a movement that recognizes the value of sharing (some) data in an increasingly data rich world. While there is a relation to the term open access in the academic publishing world, the two should not be confused.
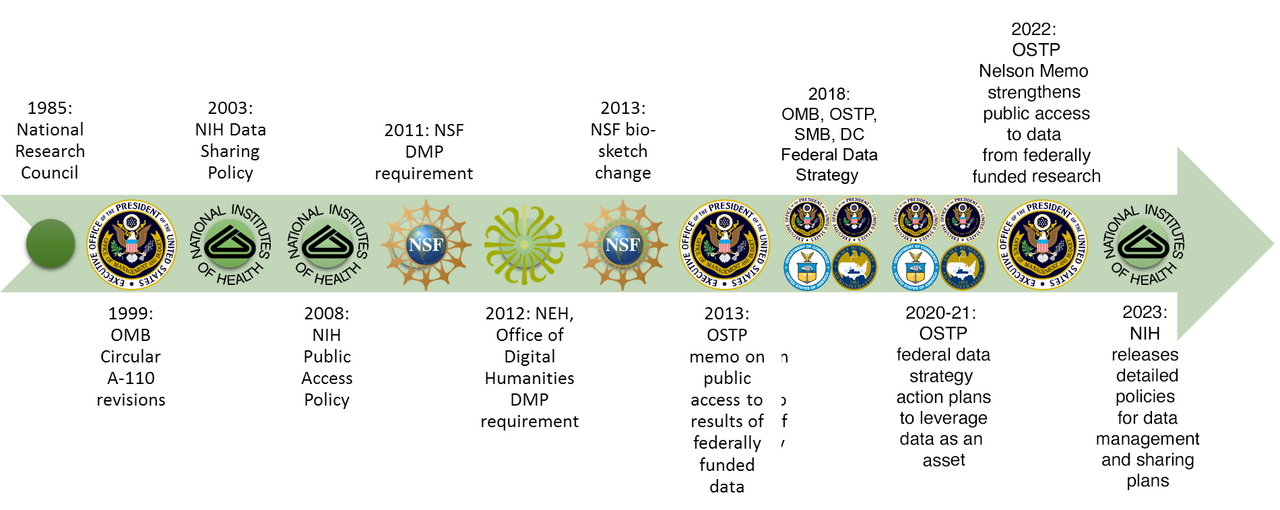
History of United States Government Policy on Open Data
In 2003 the National Institute of Health (NIH) published data sharing requirements for all federally funded medical research with budgets greater than $500,000.
In 2011 the National Science Foundation (NSF) adopted a data sharing policy.
Also, in 2011 the National Endowment for the Humanities (NEH) started to require Data Management Plans.
In 2013 the Office of Science and Technology Policy issued a memo that mandates all federal agencies with more than $100M in R&D expenditures to "develop plans to make the published results of federally funded research freely available to the public within one year of publication and requiring researchers to better account for and manage the digital data resulting from federally funded scientific research." (Holdren 2013).
In 2018 the President’s Management Agenda laid out a new Cross-Agency Priority (CAP) Goal: Leveraging Data as a Strategic Asset to develop and implement a comprehensive Federal Data Strategy. Based on this initiative, with input from the full spectrum of government and non-government stakeholders, the first government-wide data strategy was developed, along with the 2021 Action Plan for implementation.
In 2022 the Office of Science and Technology Policy issued a memo known as the Nelson Memo, with the intent to ensure "Free, Immediate, and Equitable Access to Federally Funded Research." This document seeks to remove all publication embargoes on both publications and data that result from federally funded research. Additionally, it calls for agencies publishing research results to abide by the FAIR principles for data sharing and encourages the use of machine-readable metadata in descriptions of research products.
In 2025 the Office of Science and Technology Policy issued a memo on Agency Guidance for Implementing Gold Standard Science in the Condut & Management of Scientific Activies. This memo continues to encourage the publication of research data, "Agencies should encourage depositing raw data and code that contributes to research outcomes in publicly accessible repositories, where appropriate, to facilitate exact replication and support reproducibility through diverse methodological approaches."
Apart from the Research Data Services found in this guide, there are several other campus departments that provide data services to the research community. Please explore the options below based on your needs.
The Office of the Vice Provost for Research and Scholarship (OVPRS) consists of over 250 professionals with expertise in guiding faculty, staff, and learners through the entire research lifecycle, from project conception and grant submission to sharing results with the world and creating commercial opportunities. The mission of the Office of the Vice Provost for Research & Scholarship is to work with the faculty, students, and staff to foster and encourage the highest quality research and creative activities.
OVPRS oversees a variety of resources for researchers at the University of Miami. These resources include training, funding, core facilities, information technology, software applications, how to commercialize your research, and a new faculty research guide. Please see their set of systems and services and their set of FAQs for more information.
Applications provided by the OVPRS and UHealth IT include:
The Miami Clinical and Translational Science Institute (CTSI) provides crucial support and resources to investigators as they plan and implement research studies and clinical trials that aim to improve the health of patients and communities. The Miami CTSI provides resources for:
The Frost Institute for Data Science and Computing (IDSC)'s goal is to enable discovery through data-intensive research in fields ranging from medicine to earth sciences, urban planning, digital humanities, and business. IDSC also strives to enhance Data Science understanding among their students and the public, helping individuals of all ages including underrepresented minorities develop the STEM skills needed for professional success in the 21st century. As a member of the University of Miami’s Frost Institutes of Science and Engineering, IDSC supports basic and applied research initiatives throughout the University of Miami and with other leading institutions around the world.
IDSC provides several services based on their built environment for High Powered Computing (HPC). These include compute time on Pegasus and/or Triton, the HPC clusters that IDSC maintains, storage options for data, and advanced consulting for research needs on any of the UM Campuses. Please see their services for more information.
Additionally the IDSC provides free consultation for grant preparation and DMPs that will include the use of their HPC in the proposed research.
There are many online resources for self-learners to explore and discover Data Management. The list of suggested sites below provides a starting point for those motivated to follow through.