Accessibility Options:
subjectId: 690583
visibleTabCount: 10
How to choose the right graph for your data.
The data visualization catalogue.
Declutter-story telling with data.
Charts Do's and Don'ts.
Practical Rules for Using Color in Charts
Choose Appropriate Visual Encodings
Research Data & Open Scholarship | Data & Visualization Services | Biomedical Data Services | GIS | Research Analytics & Impact Services | Research Data Management | Scholarship@Miami
Welcome to the Biomedical Data Guide!
- The Biomedical Data guide is designed to connect you to Biomedical Research resources available via UM Libraries. This guide provides information about statistical tests, finding data sources, data visualization resources, file naming and structure, and electronic laboratory notebooks. You can also access the learning resources offered in my workshops, covering topics in R, SPSS, Tableau, REDCap, GraphPad Prism, and Meta-Analysis.
- This guide is constantly evolving, and contact me at thilani.samarakoon@miami.edu if you find a tool or learning resource that could be included here.
Subject Specialist

What is data visualization?
Data visualization is the visual presentation of data and an essential step in data analysis.
As the image below illustrates, a good visualization should be the intersection of data, function, and design.
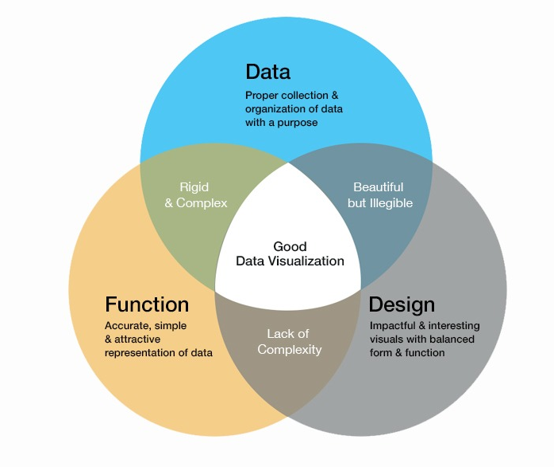
Visual elements like graphs, maps, tables, and plots help the audience identify trends, patterns, and distributions in the data. Data visualization is useful in converting complex data sets into meaningful information that the user quickly understands. Researchers in biomedical fields collect large amounts of data that are becoming increasingly complex.
Resources
- The Data Visualization Catalogue
- Better Data Visualizations: A Guide for Scholars, Researchers, and Wonks
- Designing Data Visualizations
- A Practitioner's Guide to Best Practices in Data Visualization
- Beginning Data Science in R: Data Analysis, Visualization, and Modelling for the Data Scientist
- Tasks, Techniques, and Tools for Genomic Data Visualization
Creating a data visualization
Biomedical fields collect large amounts of data that are becoming increasingly complex. Data visualizations continue to develop tools to create new kinds of visualizations to address this complexity.
How do we create a meaningful visualization?
- Know your audience
- Choose the right graph/table
How to choose the right graph for your data.
The data visualization catalogue.
- Declutter
Declutter-story telling with data.
Charts Do's and Don'ts.
- Focus attention
Practical Rules for Using Color in Charts
Choose Appropriate Visual Encodings
Tools
Power BI is designed for converting your data into visuals with advanced data analysis and AI capabilities.
It is supported by the UMIT.
GraphPad Prism is a great graphing solution which creates elegant visuals. It can also be used as a data analysis tool.
It is supported by the UMIT.
Tableau is capable of creating high-quality visualizations and dashboards.
Tableau offers free one-year licenses to students. Click to request your license.
Tableau online resources are a great way to start learning the software.
R is a free software environment for creating visualizations. It requires some programming knowledge.
R offers additional packages to cater to any visualization task.
ggplot2: Creates custom plots. Refer to Cookbook for R to learn ggplot2.
GGally: Creates correlation matrix and survival plots.
gplots: Creates heat maps, Venn diagrams.
leaflet: Builds interactive maps.
Click to learn more about R packages
Infographics create visual communications and provide an overview of the topic.
AHRQ Research Data Infographics
Picktochart
Canva
Meta-Analysis: Getting Started
"Meta-analysis is the statistical combination of results from two or more separate studies."
Cochrane Handbook for Systematic Reviews of Interventions, version 6.2
Meta-analyses are a subset of systematic reviews and play a fundamental role in evidence-based healthcare. It comes at the top of the evidence-based medicine pyramid.
Eg: Study is restricted to a certain age group, symptoms experienced by the participants, location, written language
Cochrane Handbook for Systematic Reviews of Interventions, version 6.2
Meta-analyses are a subset of systematic reviews and play a fundamental role in evidence-based healthcare. It comes at the top of the evidence-based medicine pyramid.
Why do we perform a Meta-analysis?
- Combining studies in a meta-analysis can increase the overall statistical power to detect an effect.
- Help make a valid decision about intervention and identify the reasons for the variation.
- Settles controversies arising from apparently conflicting studies or evaluates new hypotheses.
Establish your research question
Consider using PICOS tool
● Patient/Person: Who does this relate to?
● Intervention (or cause, prognosis): What is the intervention or cause?
● Comparison (Is there something to compare the intervention to?)
● Outcome (What outcome are you interested in?)
● Study type
Has this question already been answered?
- Search the published literature: Cochrane Library, Campbell Collaboration
- Registered as an ongoing review: Prospero, Cochrane
Literature Search
It is important to obtain all relevant studies to avoid bias and include all evidence in the study. The search requires searching multiple databases and gray literature.Establishing inclusion/exclusion criteria for the search
Inclusion/exclusion criteria are established before conducting the literature search to set boundaries for the review.Eg: Study is restricted to a certain age group, symptoms experienced by the participants, location, written language
Data Extraction and Synthesis
Data should be extracted based on the previously defined interventions and outcomes. You can customize your data extraction form using the Cochrane data extraction template.
Statistical analysis is a two-step process.
Source: Introduction to SAS. UCLA: Statistical Consulting Group.
Quantitative data needed for a Meta-Analysis
- Dichotomous variables (e.g., deaths, patients with at least one stroke)
- Count data (e.g., number of strokes)
- Continuous variables (e.g., blood pressure, pain score)
- Sample size
- Sensitivity, specificity
- Survival data
Statistical analysis
Data synthesis will include numerical and graphical presentations of the data.Statistical analysis is a two-step process.
- First stage: summary statistic is calculated for each study to describe the observed intervention effect.
- Second stage: A summary (combined) intervention effect estimate is calculated as a weighted average of the intervention effects estimated in the individual studies.
Statistical models for Meta-analysis
- Fixed effect model
- assumes all studies are estimating the same (common) treatment effect.
- Random effects model
- assumes observed estimates of treatment effect can vary across studies.
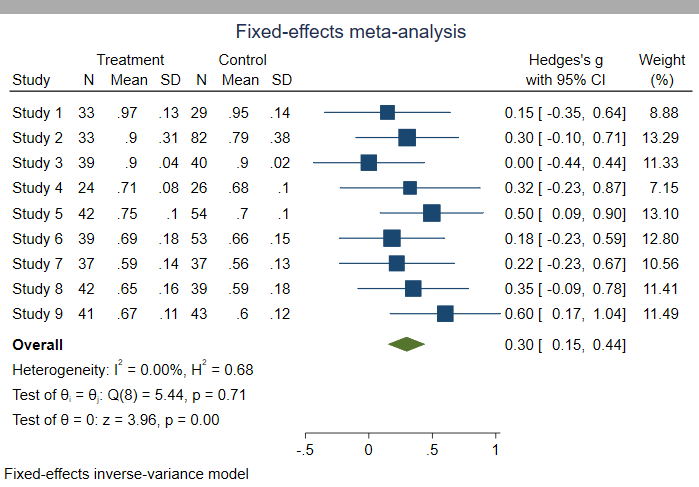
Forest plots
Forest plot summarizes the informaiton from individual studies and shows the estimated common effect.Source: Introduction to SAS. UCLA: Statistical Consulting Group.
Resources and Tools
Commonly used databases for the literature search
- MEDLINE - Biomedical literature database
- CENTRAL - Cochrane Central Register of Controlled Trials
- CINAHL - Cumulative Index to Nursing and Allied Health Literature
- Embase - Biomedical and pharmacological (including MEDLINE titles)
- PsycInfo - Psychological, behavioral, social, and health sciences research
- ClinicalTrials.gov - database of clinical studies conducted around the world
- Web of Science, Scopus, Google Scholar
Systematic review management software
Statistical analysis software
Training
- Cochrane Interactive Learning: Calder medical library offers access to the online course.
- Revman training videos
Other tools and resources
- Cochrane Handbook for Systematic Reviews of Interventions: This is the official guide that describes in detail the process of preparing and maintaining Cochrane systematic reviews on the effects of healthcare interventions
- Systematic review resource guide at Calder medical library.
Data.gov lounged in 2009, offers public access to data sets generated by the U.S. Federal Government. You will find federal, state, and local data, tools, and other resources to conduct research. The site contains more than 180 000 data sets and offers several filters to narrow your search.
The site contains health-related data sets on various topics, including community health, medical devices, substance abuse, and hospitals. Data sets are organized by the topic. Some data sets are readily available, and in other cases, you will be directed to another site.
The site is home to more than 350,000 research studies conducted in more than 200 countries. The U.S. National Library of Medicine runs this resource.
The site offers a comprehensive guide on how to customize a search.
https://clinicaltrials.gov/ct2/help/how-find/index
NCHS is a part of the Centers for Disease Control & Prevention (CDC) and provides data and health statistics on crucial public health topics.
Cancer Query Systems - allows access to cancer data stored in an online database. The web-based interface is easy to use and retrieve statistics using a query-based system.
SEER*Stat - The data downloaded can be analyzed using the SEER* Prep and SEER*Stat statistical software.
Please refer to the webpage for installation instructions and tutorials.
NDA collects and stores data from and about human subjects across many research fields. It holds data collected by researchers funded by the National Institute of Alcoholism and Alcohol Abuse (NIAAA) and autism researchers. Also, it stores data from the Adolescent Brain and Cognitive Development Study, the Human Connectome projects, and the Osteoarthritis Initiative.
The website offers access to national, state, and regional data collected via the National Survey of Children’s Health (NSCH). The survey collects data on mental health, dental health, development, and many other child health indicators to improve child, youth, family, and community health and well-being. You can submit a data request to access the raw data or use the interactive query base system to search the data.
The site contains health-related data sets on various topics, including community health, medical devices, substance abuse, and hospitals. Data sets are organized by the topic. Some data sets are readily available, and in other cases, you will be directed to another site.
The site is home to more than 350,000 research studies conducted in more than 200 countries. The U.S. National Library of Medicine runs this resource.
The site offers a comprehensive guide on how to customize a search.
https://clinicaltrials.gov/ct2/help/how-find/index
NCHS is a part of the Centers for Disease Control & Prevention (CDC) and provides data and health statistics on crucial public health topics.
- Health, United States, is an annual report on trends in health statistics. It includes trend tables and figures on selected topics such as mortality, life expectancy, causes of death, and health care expenses, among other topics. https://www.cdc.gov/nchs/data/hus/hus18.pdf
- FastStats is a site within the NCHS that offers quick access to data, statistics, and reports on specific health topics. The topics are organized in alphabetic order and will direct you to more resources on the topic.
- The National Vital Statistics System provides access to most of the data on birth and deaths in the United States. There are links on the webpage that links to statistical reports, data sources, and data visualizations.
Cancer Query Systems - allows access to cancer data stored in an online database. The web-based interface is easy to use and retrieve statistics using a query-based system.
SEER*Stat - The data downloaded can be analyzed using the SEER* Prep and SEER*Stat statistical software.
Please refer to the webpage for installation instructions and tutorials.
NDA collects and stores data from and about human subjects across many research fields. It holds data collected by researchers funded by the National Institute of Alcoholism and Alcohol Abuse (NIAAA) and autism researchers. Also, it stores data from the Adolescent Brain and Cognitive Development Study, the Human Connectome projects, and the Osteoarthritis Initiative.
The website offers access to national, state, and regional data collected via the National Survey of Children’s Health (NSCH). The survey collects data on mental health, dental health, development, and many other child health indicators to improve child, youth, family, and community health and well-being. You can submit a data request to access the raw data or use the interactive query base system to search the data.
The site offers public access to data on substance use and mental health. In addition, it provides data analysis tools: Public-use Data Analysis System (PDAS) and restricted-use Data Analysis System (RDAS).
The survey collects data about the American public’s knowledge of, attitudes toward, and use of cancer- and health-related information. The data sets help researchers identify how adults use different communication channels to understand and obtain health-related information. HINTS data are free to download and analyze.
NTDBRDS is maintained by the American College of Surgeons and is the most extensive collection of U.S. trauma registry data. The researchers must submit an online request to obtain the data sets that are available at a cost.
HCUP's databases contain information on inpatient stays, emergency department visits, and ambulatory care.
Nationwide HCUP Databases
National Inpatient Sample (NIS)
- Kids’ Inpatient Database (KID) - KID Database Documentation
- Nationwide Ambulatory Surgery Sample (NASS) - NASS Database Documentation
- Nationwide Emergency Department Sample (NEDS) - NEDS Database Documentation
- Nationwide Readmissions Database (NRD) - NRD Database Documentation
State-specific HCUP Databases
- State Inpatient Databases (SID) - SID Database Documentation
- State Ambulatory Surgery and Services Databases (SASD) - SASD Database Documentation
- State Emergency Department Databases (SEDD) - SEDD Database Documentation
Some of these data sets do not offer free access, and purchase details can be found at Purchasing FAQs.
HCUPnet
HCUPnet is a part of the HCUP project and offers a free on-line query system to access data on inpatient stays (NIS, KID, SID, and NRD), emergency department visits (NEDS, SEDD, SID), and community (SID). You create an analysis set-up by clicking on “Create new analysis.” Once the analysis is completed, it can be customized using the “My analysis” menu.
How do we select the right statistical test?
This page is created to help you choose a statistical test based on your study design, purpose, and type of data. The tests are divided into two main categories: parametric and nonparametric. Parametric tests assume that your data fit the normal distribution. Nonparametric tests do not rely on any distribution and often have parametric equivalents.
The types of data/level of measurement mainly fall into two broad categories: continuous and categorical. By clicking on each test tab, you can learn more about the assumptions associated with the test and when to use it.
The types of data/level of measurement mainly fall into two broad categories: continuous and categorical. By clicking on each test tab, you can learn more about the assumptions associated with the test and when to use it.
Parametric Tests
Continuous Data
- Compare the means of two independent samples.
- Assumptions: Normal distribution (Shapiro-Wilk test), homogeneity of variances (Levene's test), independence of observations, no outliers.
- SPSS Demo
- Compare the means of two dependent samples.
- Assumptions: Normal distribution (Shapiro-Wilk test), homogeneity of variances (Levene's test), independence of observations, no outliers
- Compare independent sample means for more than 2 groups. Post Hoc - if equal of variances assumed select Tukey test. Otherwise, select Games-Howell.
- Assumptions: Normal distribution (Shapiro-Wilk test), homogeneity of variances (Levene's test) independence of observations, no outliers.
- Compare means of 3 or more groups with the same participants.
- Assumptions: Normal distribution (Shapiro-Wilk test), homogeneity of variances (Levene's test) independence of observations, no outliers, sphericity (Mauchly’s test).
- Examine the linear association and direction between two continuous variables. It takes a value between +1 to -1.
- Assumptions: Association between the two variables is linear, Normal distribution (Shapiro-Wilk test), no outliers.
- Examine the linear association between a continuous outcome variable, and one or more independent variables.
- Assumptions: There should be a linear relationship between the 2 variables, no significant outliers, independence of observations, Normality.
Categorical Data
- Examines the probability that an observation falls into one of two categories of a dichotomous dependent variable based on one or more independent variables that can be either continuous or categorical
- Assumptions: Dependent variable is dichotomous, independence of observations, linear relationship between any continuous independent variables and the logit transformation of the dependent variable.
Non-Parametric Tests
Continuous or ordinal Data
- Compare the means of two independent samples when the normality assumption is violated. (alternative to an independent t-test)
- Assumptions: Independence of observations, distributions of the independent variable should have the same shape, independent variable consists of two categorical groups.
- Compare the means of two dependent samples when the normality assumption is violated. (alternative to the dependent t-test)
- Assumptions: Independent variable consists of two categorical groups, dependent variable measured at the ordinal or continuous level, distributions of the independent variable should have the same shape.
- Compare independent sample means for more than 2 groups when the normality assumption is violated. (alternate to ANOVA, an extension of Mann-Whitney U test)
- Assumptions: Independence of observations, independent variable consists of two or more categorical groups.
- Compare means of 3 or more groups with the same participants when the assumptions of ANOVA with repeated measures are violated or the dependent variable measured is ordinal. (alternate to ANOVA with repeated measures)
- Assumptions: A group is measured 3 or more times, random sampling.
- Examine the linear association and direction between continuous or ordinal variables when the assumptions have failed for a Pearson correlation. It takes a value between +1 to -1. (alternate to Pearson correlation)
- Assumptions: There is a monotonic relationship between the two variables.
- Examine the association and direction between continuous or ordinal variables. Specially applied to small sample sizes and for variables with many ranks. It takes a value between +1 to -1. (alternate to Pearson correlation and Spearman correlation)
- Assumptions: There is a monotonic relationship between the two variables.
Categorical Data
- Compare sample proportions to check if there is an association between the categories. A residual analysis will identify the specific cells that make the greatest contribution to a significant chi-square test.
- Assumptions: Independence of observations, expected cell count assumption (expected cell counts are all greater than 5)
- SPSS Demo
- Compare sample proportions to check if there is an association between the categories. Used for small samples.
- Assumptions: Independence of observations, if the expected cell count is less than 5 for any cell, use Fisher’s exact test.
- SPSS Demo
- Determine the differences on a dichotomous dependent variable between two related groups.
- Assumptions: Dichotomous variables, dependent variables should be mutually exclusive.
Other commonly used tests:
- This method is used to study the reliability of the scale used in a survey (commonly used with Likert scale questions).
- The scale ranges from 0-1. If the alpha is 0.7 or above, the measure can be considered reliable. For example, a survey was designed with 10 questions to measure if the students are happy at school.
- The questions are on a Likert scale. The researcher can survey a sample and carry out the Cronbach analysis to estimate the reliability.
- This test is used to study the inter-rater reliability when two raters are evaluating a variable on a categorical scale.
- The scale ranges from 0-1. There is no clear cut-off for a good agreement. Normally, 0.6-0.8 is considered good.
- There are a few assumptions to be met before conducting the test. The categories should be mutually exclusive, the raters are independent, and the same raters evaluate all the questions.
- This test is used to study the inter-rater reliability when two or more raters evaluate a variable on a categorical scale.
- If the raters are not fixed, meaning the same 2 raters are not evaluating the questions.
Resources:
- Statistical methods for the analysis of biomedical data, Woolson, Robert F.; Clarke, William R. (William Radue), New York: Wiley-Interscience, [2002]
- https://statistics.laerd.com/
- Parametric and Non-parametric tests for comparing two or more groups
- Choosing a statistical test
Reproducibility and Related Terminology
Reproducibility crisis in research arises due to the lack of sufficient instructions/details to repeat an experiment to obtain the same results. This could be related to the experiments or the analysis.
It is important that we understand the difference between repeatability, reproducibility, and replicability. Below is the terminology established by the Association for Computing Machinery.
Repeatability (Same team, same experimental setup)
Goodman et al. (2016) proposed methods reproducibility, results reproducibility, and Inferential reproducibility as broader categories for research reproducibility.
It is important that we understand the difference between repeatability, reproducibility, and replicability. Below is the terminology established by the Association for Computing Machinery.
Repeatability (Same team, same experimental setup)
- The measurement can be obtained with stated precision by the same team using the same measurement procedure, the same measuring system, under the same operating conditions, in the same location on multiple trials. For computational experiments, this means that a researcher can reliably repeat her own computation.
- The measurement can be obtained with stated precision by a different team using the same measurement procedure, the same measuring system, under the same operating conditions, in the same or a different location on multiple trials. For computational experiments, this means that an independent group can obtain the same result using the author's own artifacts.
- The measurement can be obtained with stated precision by a different team, a different measuring system, in a different location on multiple trials. For computational experiments, this means that an independent group can obtain the same result using artifacts which they develop completely independently.
Goodman et al. (2016) proposed methods reproducibility, results reproducibility, and Inferential reproducibility as broader categories for research reproducibility.
Guidelines
NIH principles and guidelines for reporting preclinical research
The NIHPG include the better performance of statistical analysis, transparency in reporting, data and material sharing, consideration of refutations, and consideration of establishing best practice
guidelines. These guidelines encourage authors to provide complete information about their studies for better reproducibility.
Citation of BioResources in journal Articles (CoBRA)
This provides a checklist for the citation of bioresources (biological samples, data, and databases) used in scientific journal articles.
Animal Research: Reporting of In Vivo Experiments (ARRIVE)
This is a checklist of recommendations to improve the reporting of research involving animals – maximizing the quality and reliability of published research, and enabling others to better scrutinize, evaluate and reproduce it.
The TOP Guidelines
Transparency and Opened Promotion (TOP) provides guidelines to enhance transparency in journal publications. The main categories include citation, data transparency, analytical methods (code) transparency, research materials transparency, preregistration of studies, preregistration of analysis plans, replication.
Equator network
Enhancing the QUAlity and Transparency Of health Research (EQUATOR) is a network is an international initiative that seeks to improve the reliability and value of published health research literature by promoting transparent and accurate reporting and wider use of robust reporting guidelines.
PRISMA
Preferred Reporting Items for Systematic Reviews and Meta-Analyses (PRISMA) is an evidence-based minimum set of items for reporting in systematic reviews and meta-analyses. PRISMA primarily focuses on the reporting of reviews evaluating the effects of interventions.
DRYAD: Best practices for creating reusable data
DRYAD is a nonprofit membership organization that is committed to making data available for research and educational reuse. These guidelines help make the datasets findable, accessible, interoperable, and reusable (FAIR).
The NIHPG include the better performance of statistical analysis, transparency in reporting, data and material sharing, consideration of refutations, and consideration of establishing best practice
guidelines. These guidelines encourage authors to provide complete information about their studies for better reproducibility.
Citation of BioResources in journal Articles (CoBRA)
This provides a checklist for the citation of bioresources (biological samples, data, and databases) used in scientific journal articles.
Animal Research: Reporting of In Vivo Experiments (ARRIVE)
This is a checklist of recommendations to improve the reporting of research involving animals – maximizing the quality and reliability of published research, and enabling others to better scrutinize, evaluate and reproduce it.
The TOP Guidelines
Transparency and Opened Promotion (TOP) provides guidelines to enhance transparency in journal publications. The main categories include citation, data transparency, analytical methods (code) transparency, research materials transparency, preregistration of studies, preregistration of analysis plans, replication.
Equator network
Enhancing the QUAlity and Transparency Of health Research (EQUATOR) is a network is an international initiative that seeks to improve the reliability and value of published health research literature by promoting transparent and accurate reporting and wider use of robust reporting guidelines.
PRISMA
Preferred Reporting Items for Systematic Reviews and Meta-Analyses (PRISMA) is an evidence-based minimum set of items for reporting in systematic reviews and meta-analyses. PRISMA primarily focuses on the reporting of reviews evaluating the effects of interventions.
DRYAD: Best practices for creating reusable data
DRYAD is a nonprofit membership organization that is committed to making data available for research and educational reuse. These guidelines help make the datasets findable, accessible, interoperable, and reusable (FAIR).
Resources
The Center for Open Science partners with the community to increase the transparency and reproducibility of scientific research.
Below are a few steps we can take to improve reproducibility in research.
Below are a few steps we can take to improve reproducibility in research.
- Provide appropriate citations for data and materials
- Post data and code in a trusted repository
- Design transparency
- Preregistration of studies
- Sharing data
Background
- What does research reproducibility mean?
- Rethinking research reproducibility
- Reproducibility in Science: Improving the Standard for Basic and Preclinical Research
- Reproducibility vs. Replicability: A Brief History of a Confused Terminology
Method reproducibility
- Teaching Computational Reproducibility for Neuroimaging
- Six factors affecting reproducibility in life science research and how to handle them
- The Road to Reproducibility in Animal Research
- Reproducibility and replicability of systematic reviews
Results reproducibility
File Naming
Naming your files clearly and consistently is an important part of data management. This will make data easier to locate. If you cannot tell what is in the file from reading the file name, then you need to improve your file naming convention.
File naming best practices
- Files should include only letters, numbers, and underscores/dashes.
- No special characters.
- No spaces; Use dashes, underscores, pascal case (LikeThis), or camel case (likeThis)
- Use a YYYYMMDD format for dates.
- The file name should describe their content. Remember length can be a limitation here.
- Be consistent: Use the same naming schema for related files.
- Be unique with the names even if they are stored in different folders.
- Keep a record of the naming convention.
Version control
- Use ordinal numbers (v1,v2,v3) for major version changes and decimals for minor changes (v1.1, v2.6).
- Use leading zeros so that they sort in order (e.g., 001, 002, 003).
Common elements in a file name
- Project or experiment name
- Lab name/location
- Name of the researcher
- Date of creation
- Content of the file
- Experimental condition
- Sample number
- Eg: 20201223_ProjectName_ExperimentName_Control_012
File Structure
A well-organized file structure allows you to quickly locate and track files, group similar files together, and make the archiving process more efficient. Your file structure should be easily understood by someone who is not closely engaged with your project.
File organization tips
- Decide on the file structure before you start the project. Think about the project complexity, the number of collaborators, and the length of the project.
- Be consistent.
- Create a README file.
- Organize the files systematically within folders.
- Folder and file names should reflect the content to help researchers locate data faster.
- Keep your raw data and analyzed data separately.
Hierarchical organization of data
You can divide the folders and files into distinct categories.
- Project (project stages)
- Year
- Location (geographic location, project site)
- File Type
- Team members
- Experiments (instruments, experiment types)
Resources
- Research Data Management Guide at UM Libraries
- Biomedical Research Data Management at Harvard
- Online short-seminar: Organize your files
- File naming and organizing best practices
- Folder and file naming convention – 10 rules for best practice
What is an ELN?
Electronic Lab notebooks replace your traditional paper lab notebooks. As research becomes more complex, researchers are choosing ELNs to organize their lab notes more efficiently. That is not the only application of ELNs. ELNs can be considered research management systems. ELNs are virtual workspaces that can effectively manage data and people. Further, they manage inventories of laboratory reagents and supplies, and equipment. There are multiple vendors and open-source ELN products available to experiment with.
Advantage of using ELNs
- Data can be accessed and organized from anywhere, anytime.
- Easily searchable.
- Data can be shared with an individual or a group in multiple formats. This facilitates collaborations.
- Backup and copy data become more efficient.
- Secure: data cannot be misplaced or leave the premises.
- Data management requirements by funding agencies can be met with ELNs.
- PI can monitor data and documentation.
Choosing an ELN
Below are a few key factors to consider when choosing an ELN for your laboratory.
- Identify key features and requirements for your lab.
- Test out a few products before purchasing. Most of the vendor products offer free trial periods and training videos. This is an excellent way to explore the software and assess if it fits your laboratory requirements. Alternatively, you can talk to peers or other institutes using the software to get their feedback.
- Cost: There are Implementation fees, maintenance fees, and training fees associated with the purchase of the software.
- Security: Most of the ELNs provide compliance with FDA 21 CFR Part 11, which regulates electronic documentation and signatures. The ELNs allow the group to customize individual and group access permissions. Not all members of the group require the same access privileges.
- Meet the best practice of organizing, sharing, and archiving data
Lists of ELNs
Vender products
I have listed a few products here. For a comprehensive list, please visit the University of Utah Libraries guide on ELNs.
- Docollab: This is a collaborative workspace for projects, tasks, documents, spreadsheets, and diagrams. All the content is stored and transferred in encrypted form and Docollab's infrastructure undergoes continuous monitoring and auditing in compliance such as HIPPA Business Associate Amendment.
- LabArchives: This is a browser-based platform that is used to manage laboratory data and help to organize the workflow in a research laboratory. Its products include ELN for research, inventory, and scheduling.
- RSpace: This is an affordable and secure enterprise-grade Electronic Lab Notebook (ELN) that catalyzes research and allows organizations to enjoy the benefits, efficiencies, and long-term cost savings of centralized, paperless data storage, as well as lab management, IP protection, secure collaboration, sample tracking and integration with the institute’s existing archiving system.
Open-source products
- Cynote: This is a laboratory notebook using a version control system and independent date-time stamping (as notarization), in order to ensure record accountability, auditing, and conforming to US FDA 21 CFR 21's rule on electronic records.
- LabJ-ng: This is a laboratory notebook for organic chemists. It has a client-server architecture with a web browsers interface. Data is stored on MySQL database. Chemical reactions are drawn in the java applet window. See project website for example.
- MyLabBook: MyLabBook is a free and open-source electronic lab notebook (ELN) built on the Drupal v.8-9 CMS. The basic installation provides capabilities for collecting, displaying, and sorting data with a sample data set and can be modified for different experiments. It can easily accommodate hundreds of users with a role-based permission system.
Resources
- Electronic Lab Notebooks: What they are (and why you need one)
- Biomedical Research Data Management at Harvard
- Keeping a Laboratory Notebook
- NNLM guide on Electronic Laboratory Notebook
Workshops
I conduct a workshop series in the Fall and Spring covering topics in R, SPSS, Tableau, REDCap, GraphPad Prism, and Meta-Analysis.
Multiple workshops are available in the Fall and Spring semesters.
Fall Workshops: Coming soon!
Training Resources
- Getting Started with R for Data Analysis (download link)
R is an open-source software environment for statistical computing and graphics. This workshop is designed to introduce R, RStudio, and R Markdown. You will learn to install R packages and utilize their functionalities for exploratory data analysis (EDA). It covers basic data types, importing data, cleaning and plotting data, and analyzing relationships between variables. Previous experience with R is not necessary. The .R file is the script file and can be opened in RStudio or a notepad.
- Data visualization with R (download link)
The tutorial covers topics on creating visualizations using R packages such as ggplot2. This covers basic plots and best practices in data visualization. Some experience with R is preferred.
- Introduction to REDCap and its Data Management Capabilities (download link)
REDCap (Research Electronic Data Capture) is a Web-based application that allows you to quickly build and manage databases and online surveys. The first half of the workshop will show you how to: build forms to enter data extracted from any source; use it as a survey platform; produce online summary statistics and graphics; make analyzable, anonymized datasets; export data to Excel and major statistical packages like R, SAS, SPSS, STATA, and other basic concepts. The second part of this workshop will share best practices for research data management within the REDCap application. Building upon concepts from the first half of the workshop, the second half will provide guidance on using REDCap’s tools and applications to: protect sensitive data; appropriately name variables; assess data quality; and prepare data to be shared.
- Systematic Reviews and Meta-Analysis: An Introduction (download link)
This workshop aims to give you a basic understanding of the steps of conducting a meta-analysis. Meta-analysis is a statistical technique for combining data from multiple studies on a particular topic to produce an overall statistic. Meta-analysis is an intensive research process involving several critical steps from the literature search, data extraction to statistical analysis. This workshop will help you understand the meta-analysis process and help you plan to conduct one.
- Introduction to GraphPad Prism (download link)
GraphPad Prism is available via UMIT. This workshop is designed to introduce you to GraphPad Prism software. Prism is a statistical software that follows a drop-down menu-based interface to conduct data analysis. This workshop will cover topics on navigating the menu, importing data, selecting data tables, creating graphs, and data analysis.
- SPSS Basics for Research and Data Analysis (download link)
The SPSS software is available for download via UMIT. This workshop is designed for new SPSS users. It provides an introduction to the SPSS software program, including its software environment, importing data, descriptive statistics, transforming variables, selecting and splitting data, and visualization. The folder also contains the data files (.sav) mentioned in the tutorial.
- AI Tools for Data Analysis and Visualization
This workshop introduces participants to three powerful AI tools Copilot, Ninja AI, and Julius AI and demonstrates how they can enhance research productivity. Attendees will learn how these tools can summarize data sets, support coding summarization tasks, and generate effective visualizations. Through practical examples, participants will gain an understanding of when and how to use each tool effectively, as well as best practices for responsible AI use.
Additional resources:
Data and Visualization Services Department offers additional workshops and training resources. Please check out the complete list here.